Lexicon Table: Full Documentation
The lexicon table is used to search all of the lexical entries in the database: reconstructed proto-forms from various publications; lexical data from Tibeto-Burman languages; Chinese comparanda; and select forms from languages which have contributed loanwords into Tibeto-Burman languages (Nepali, Old Mon, Proto-Hmong-Mien, Thai, etc.).
The lexicon table is available through a drop-down menu in the upper right-hand corner of the interface: 'Select... > Lexicon'.
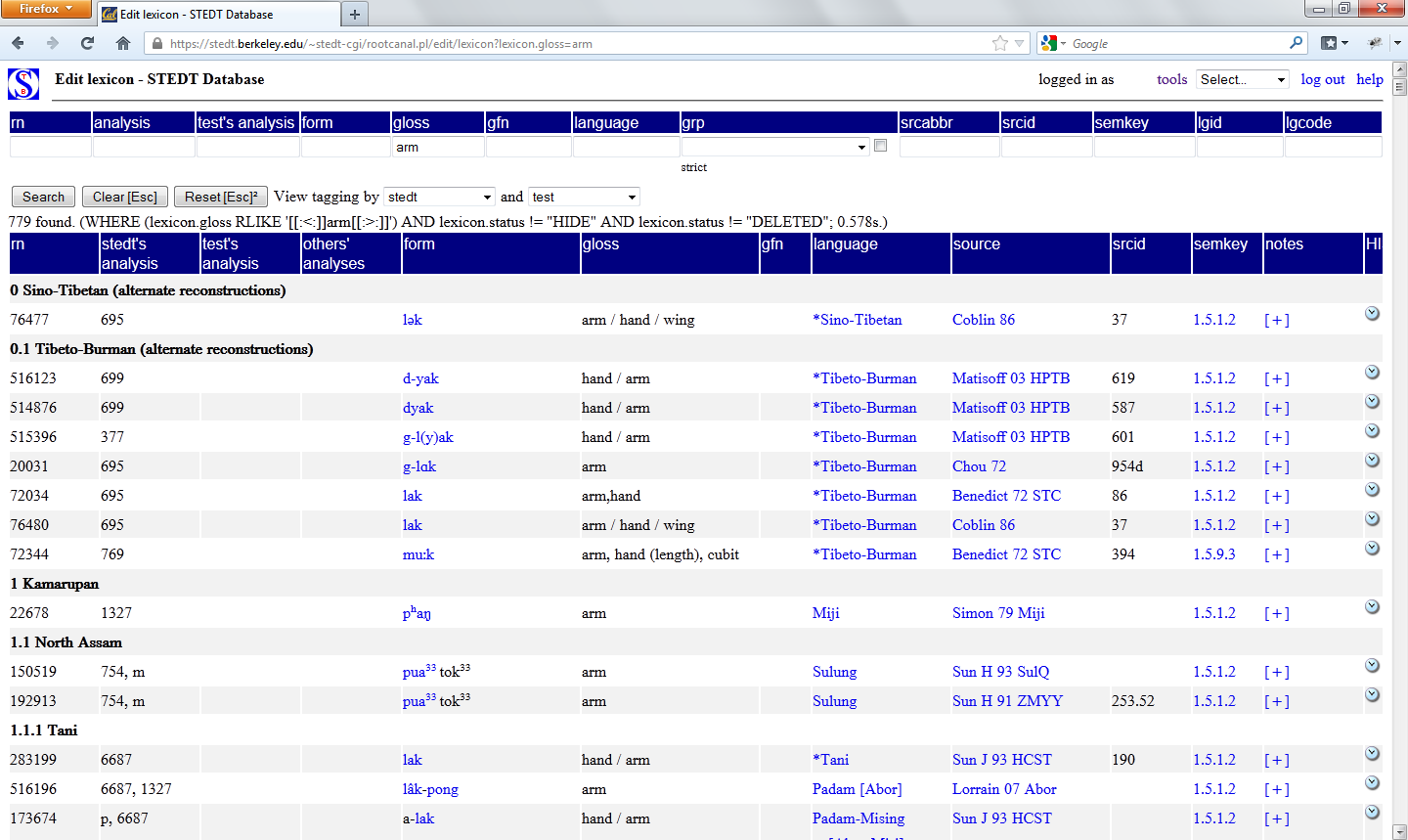
The lexicon table has two sections: the search fields (upper row) and the search results (lower rows), with fifteen different fields:
- rn (reference number)
- (stedt's) analysis
- [your username]'s analysis
- others' analyses
- form
- gloss
- gfn (grammatical function)
- language
- grp (language group)
- srcabbr (source abbreviation -- search only) / source (results only)
- srcid
- semkey
- lgid (language id -- search only)
- lgcode (language code -- search only)
- notes (results only)
As noted above, some of these items may appear only as a search field (upper row of the table) or only in the search results (lower rows of the table).
The search results are arranged by language family, with each language family or subfamily assigned an outline number: 1.1 North Assam, 1.1.1 Tani, and so on. The language families are arranged very loosely on an east to west basis, starting with the Tibeto-Burman languages of northeast India, through Burma, the Himalayas, and on to Southwestern China. Karenic and Sinitic appear towards the end.
As one can observe in the screenshot, the first listings in the search results are listings of alternate reconstructions for Sino-Tibetan and Tibeto-Burman. These are other possible reconstructions which have been proposed in the literature for your search word. Throughout the lexicon, one can identify a reconstructed form because reconstructed forms have an asterisk preceding the language name given in the 'language' field.
The rn is the reference number, which is a unique id for each lexical record in the database. Thus, if one has a question about a particular entry, one can note down this reference number so that one can easily locate it again.
The analysis field, as it is referred to in the search fields row, allows the user to search by tag number for reflexes which have already been tagged by STEDT for a particular tag. In the search results. This field is referred to as stedt's analysis in the search results.
The [your username]'s analysis field allows the user to search by tag number for reflexes which you have tagged for that tag number. In the search results section of the table, you can enter or alter any of your tag numbers.
In the search results section of the table only, the next column is others' analyses. This allows you to see any tags that other users have entered that have not yet been approved by STEDT. This allows users to avoid duplicate tagging. The form of this field is x:#, where 'x' is a number assigned by STEDT to represent a particular user and '#' is the tag number.
The form search field searches all of the lexical entries in the database: reconstructed proto-forms from various publications; lexical data from Tibeto-Burman languages; Chinese comparanda; and select forms from languages which have contributed loanwords into Tibeto-Burman languages (Nepali, Old Mon, Proto-Hmong-Mien, Thai, etc.). The lexical data in the database have been compiled from many different sources, and are presented as transcribed by the researcher who collected the data. Thus, the same language variety may be transcribed in a number of different ways. Some transcriptions are in the International Phonetic Alphabet (IPA), while others are in romanization systems devised by the researchers who originally collected the data. Searches in Chinese characters or in Devanāgarī-based scripts are not supported.
The gloss field will search the database by the English meaning associated with each lexical entry. It will return partial matches associated with word boundaries, so a search for 'fish' will return results such as 'dried fish', 'fish sauce', and 'catch fish', but not 'fishing' or 'crayfish'. The search results may include a number of items which include the search term but are not directly related to your search. For example, a search for 'fish' includes gizigon 'sticks (iron, used for roasting fish etc. on fire)' from Bodo (Bhat 1968).
gfn is the form's grammatical function; this data point is not available for most entries in the database, but is given where available.
The language field will restrict the search by language name. For some languages, the database contains multiple varieties of the language. For example, for Tibetan, the database has 'Tibetan (Written)', 'Tibetan (Alike)', 'Tibetan (Amdo:Blabrang)', 'Tibetan (Amdo:Zeku)', 'Tibetan (Balti)', 'Tibetan (Batang)', 'Tibetan (Jirel)', 'Tibetan (Khams:Dege)', 'Tibetan (Lhasa)', 'Tibetan (Sherpa)', 'Tibetan (Spiti)', and 'Tibetan (Xiahe)'. Additionally, different researchers may have contributed data for some of these varieties, in which case there will be multiple entries for the same language variety for the same gloss. For additional information about the languages included in the database, see the language groups browser.
The grp field is a drop-down menu of the language groups contained in the database. When a language group is selected from the drop-down menu, the database will return only lexical entries for languages of that language group.
The srcabbr (source abbreviation) appears in the search fields row only. This field allows the user to search the table for forms from a given source, using the source's source abbreviation, which can be located using the source bibliography. The equivalent field to the 'srcabbr' in the search results is the source field. Source gives an abbreviation for the bibliographic citation for the form; clicking on the source will open a new window with the full bibliographic citation for the form, as well as metadata about the source.
The srcid field is for internal use only.
Semkey is a unique identification string given to each semantic category. Each semkey is clickable link. By clicking on the semkey, the user is led to a webpage giving several types of analyses, as available. For more information on semkeys, see the chapter browser.
The lgid field is for internal use only.
The lgcode field is for internal use only.
The notes field contains any notes from the STEDT team about the record.
For any search, the maximum number of results returned is 10,000 entries.
These search boxes can be used in combination to return more specific results. Commonly used combinations include:
- form + gloss -- e.g. one can do a search for all entries which contain 'm' in the form and mean 'eye'.
- form + language -- e.g. one can do a search for all entries which contain 'm' in the form in Angami Naga.
- form + language group -- e.g. one can do a search for all entries which contain 'm' in the form and belong to the Tangkhulic language group.
- gloss + language -- e.g. one can do a search for all entries which mean 'fish' in Apatani.
- gloss + language group -- e.g. one can do a search for all entries which mean 'fish' in the Tani language group.
- form + gloss + language -- e.g. one can do a search for all entries which contain 'm' and mean 'eye' in Apatani.
- form + gloss + language family -- e.g. one can do a search for all entries which contain 'm' and mean 'eye' in the Tani language group.