Etyma Table: Full Documentation
The etyma table is used to search the reconstructed proto-forms or etyma in the database:
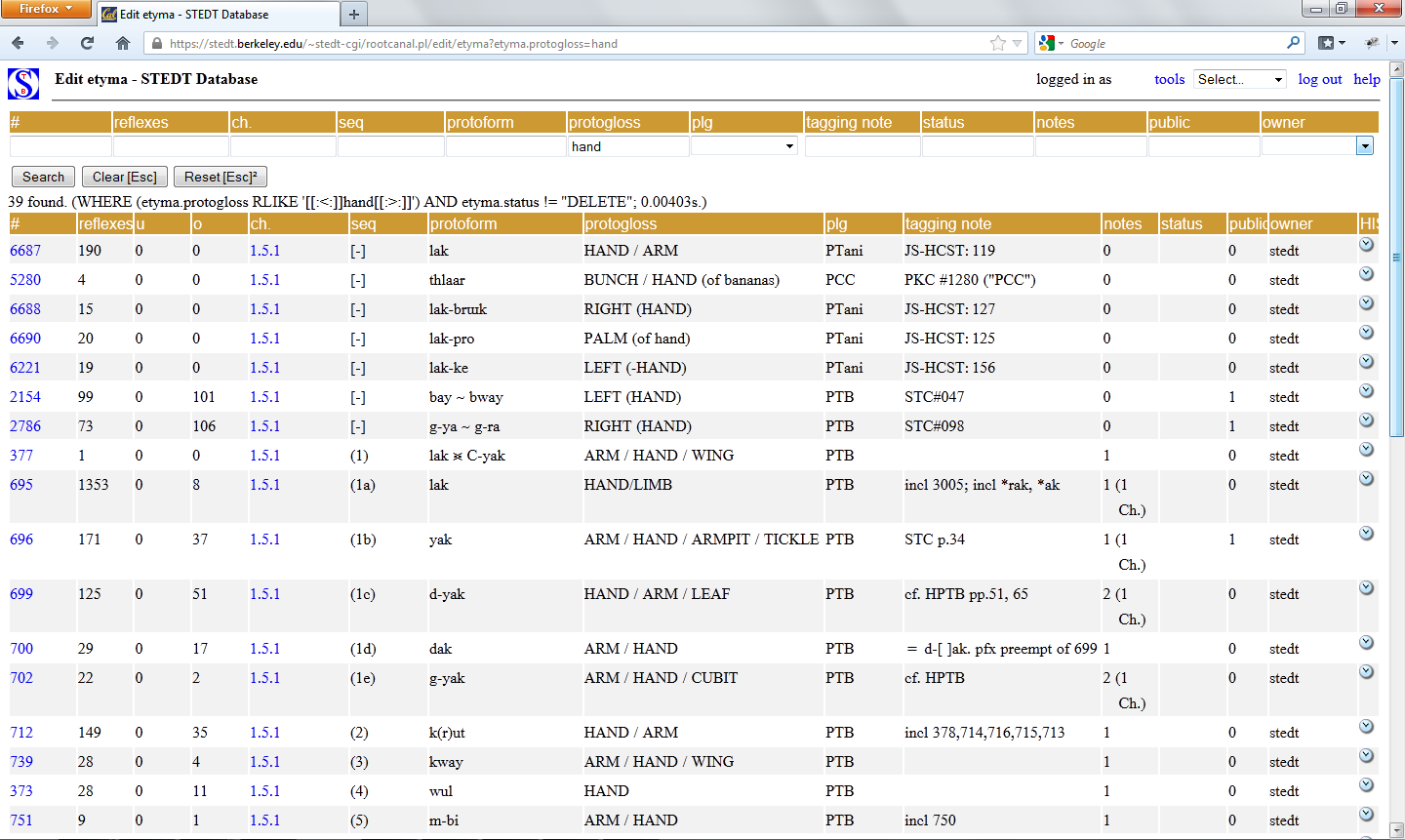
The etyma table is available through a drop-down menu in the upper right-hand corner of the interface: 'Select... > Etyma'. The etyma table has twelve search fields:
- #
- reflexes
- ch. [chapter]
- seq. [sequence]
- proto-form
- proto-gloss
- plg [proto-language]
- tagging note
- status
- notes
- public
- owner
Most commonly, the etyma table is searched by proto-form or by proto-gloss, although additional search capabilities are available, as described here. One can search the proto-form field by entering a known proto-form, or by entering a partial string, e.g. entering 'm' would yield all proto-forms which contain 'm'. One can search the proto-gloss field by entering a term in English, e.g. 'fish'; this will return all reconstructed proto-forms which contain the word 'fish', e.g. FISH, SKIN / LIP / SCALES (fish) / SHELL, FISH SCALES, and SHELL(-FISH). (Proto-glosses are given in capital letters in the etyma table.) The search results will appear in the search results (lower section) of the etyma table.
For a given gloss, there may be a number of different etyma within Tibeto-Burman. For example, there are a number of etyma which have been reconstructed for 'leaf': #824 *s-lap LEAF / LEAFLIKE PART, #293 *lay LEAF / PAPER, #708 *p(r)ak ⪤ r-pak ⪤ C-pak LEAF / PALM, #402 *s-nas LEAF, and others. Some forms may be borrowings, and there may be forms for which no etymon has yet been reconstructed.
The # field allows the user to search the etyma table by the etymon's unique tag number. This feature is useful when one has worked extensively with the STEDT database and knows the tag number of the etymon one wants to view. Each tag number has been assigned to its etymon arbitrarily.
The reflexes field search field is for internal use. The reflexes search results box indicates how many reflexes have been tagged for a particular etymon.
The chapter field allows the user to search the etyma which have been assigned to a particular chapter in the semantic categorization system. For example, inputting '1.1.2.3' into the chapter search box yields, in a new tab, all of the etyma which have been assigned to 1.1.2.3 Existence. (To view the chapters in the semantic categorization system, see the chapter browser.)
The sequence field is for internal use. It allows STEDT to order the etyma within a chapter so that an e-dissemination can be prepared.
The proto-form field allows the user to search the etyma table for a given proto-form. Thus, one can search for a particular proto-form in which the user is interested, or for a proto-form which contains a particular Proto-Sino-Tibetan or Proto-Tibeto-Burman phoneme.
The proto-gloss field allows the user to search the etyma table for etyma by English gloss.
The proto-language drop-down menu allows the user to search for some of the reconstructed forms for the various reconstructed languages contained in the database. These include: PST / Proto-Sino-Tibetan, PTB / Proto-Tibeto-Burman, PTani / Proto-Tani, PKC / Proto-Kuki-Chin, PPC / Proto-Peripheral-Chin, PNC / Proto-Northern-Chin, PSPC / Proto-Southern-Plains-Chin, PCC / Proto-Central-Chin, PM / Proto-Maraic, PNN / Proto-Northern-Naga, PCN / Proto-Central-Naga, PTk / Proto-Tangkhulic, TGTM / Proto-Tamangic, PKir / Proto-Kiranti, PQ / Proto-Qiangic, PLB / Proto-Lolo-Burmese, PL / Proto-Loloish, PKar / Proto-Karenic, IA / Indo-Aryan, and undefined.
The database does not make any attempt to reconstruct Indo-Aryan forms; when an Indo-Aryan word has been pervasively borrowed into Tibeto-Burman languages, the Indo-Aryan word is assigned a tag number so that it can be tagged in the database. Thus, 'Indo-Aryan' is included in the proto-language drop-down menu, and the user can search the database to see Indo-Aryan loans which appear with high frequency in Tibeto-Burman languages. (Please note, however, that less pervasive Indo-Aryan loans have not been assigned tag numbers. Additional Indo-Aryan loans can be viewed by searching the analysis field in the lexicon table for 'b' (e.g. 'borrowing'), 'bNep' ('borrowing from Nepalese'), 'bAssam' ('borrowing from Assamese'), 'b, Indic' ('borrowing from Indic'), 'b Hindi' ('borrowing from Hindi'), or searching the gloss field for 'Nepali', 'Sanskrit', 'Pali'. In some cases, footnotes give additional details as to the path of borrowing.) The 'undefined' etyma are mainly those which were given areal rather than genetic designations, i.e. KMR / Kamarupan, HIM / Himalayish, or other groupings which are no longer in use in the database; these etyma are in the process of being dealt with.
The tagging note field is for internal use. It is primarily used to give references to published works (such as STC and HPTB) which may have additional reflexes which should be tagged in the database; to note etyma which may need to be merged; to flag etyma as doubtful; and to provide a reference to the Chinese character in GSR which should be added to the reconstruction.
The status field is for internal use. STEDT is currently "rectifying" the database's etyma. This process involves checking that there are adequate data (in the form of reflexes) to support the proposed reconstructions; examining the tagged reflexes for plausibility; comparing each etymon with phonologically similar and/or semantically related etyma to see whether they should be merged; looking at tagged data for possible errors (typos, mistranslations, field data collection errors, encoding errors, and/or errors in converting the data from a source to a database field); adding notes to lexical entries for reflexes detailing how they evolved from the reconstructed form, when this would otherwise be unclear even to experts; examining the reconstruction's plausibility in the face of newly tagged reflexes and modifying it if necessary; and adding etymon notes to describe the support for the reconstruction (i.e. its prefix, initial, glide, and/or final) and where further research is needed.
When an etymon has been rectified, "KEEP" is entered in the status field. If, in the process of rectification, the etymon is found to be implausible, it is deleted using the delete button ("DEL") provided in the status field. If the etymon is merged with another etymon, the first etymon's reflexes are ported over to the tag number used for the second etymon, and then the first etymon is deleted using the delete button in the status field. Occasionally, if there is a technical error and the delete button does not delete the etymon, "DEL" or "DELETE" may be entered into the status field.
The notes field indicates the number, if any, of etymon notes available for the etymon.
The public field is for internal use only. This field is filled with either '0' (private) or '1' (public). Etyma with a '0' value in the public field will be marked '(provisional)' in red typeface next to the etymon with gloss when one clicks on the etymon # (far left field in the etyma table); this indicates that the etymon has not undergone rectification and is thus provisional. Etyma with a '1' value in the public field are not marked as provisional when viewed; these etyma have undergone rectification and are considered well-supported.
The owner field indicates the user who has proposed a particular etymon. This functionality is useful for quickly locating one's own etyma, for example.
When the user conducts a search using the search fields in the etyma table, the search results appear below in a table. The search results table has the same fields, with two additions: u and o, which are the third and fourth search boxes from the left. [Insert screenshot.] U stands for user and o stands for other. U will list the number of reflexes which have been tagged by you for that etymon, while o lists the number of reflexes which have been tagged by all other users for that etymon. The value for 'o' appears as 'x:y', where 'x' is a number representing another user and 'y' is the number of reflexes tagged for the etymon by user x. (In both cases, the numbers given for 'u' and 'o' reflect tags which have not yet been approved by STEDT; when the tagging has been approved, 'u' and 'o' will appear as zero, and the tagging will be added to the number of approved reflexes in the reflexes field.)