Quick-Start Guide: How to Tag
Contents:
- Overview
- Obtaining a user account
- Overview of the database
- The lexicon table
- The etyma table
- An example
- Other basic tags
Overview
The purpose of the STEDT interface is to facilitate the reconstruction of Proto-Sino-Tibetan, the theoretical language from which today's Sinitic and Tibeto-Burman languages descend. Data from Old Chinese are used to represent the Sinitic branch of Sino-Tibetan, and data from as many Tibeto-Burman languages and varieties as STEDT has been able to obtain are used to represent the Tibeto-Burman branch. (For more information on the language family and the project's theoretical background, see here and here and here.) The interface allows users to associate reconstructed Proto-Tibeto-Burman etyma with their daughter language reflexes. This process is called 'tagging'. Each Proto-Tibeto-Burman etymon has a unique tag number. You use this tag number to mark a reflex from a daughter language as belonging to that etymon.
Obtaining a user account
In order to tag, the user must have a user id and a password. Please request a password by clicking "Register" at the bottom of the splash page. When you have authenticated your password, log in using the login page. When you have logged in, use the drop-down box at the top right to choose the the lexicon table.
Overview of the database
The main interfaces of the STEDT database are the lexicon table and the etyma table. The language browser and the source bibliography provide useful metadata, and the chapter browser provides an alternate way to look at the database. In this Quick-start Guide, the lexicon table and the etyma table are introduced; interested users can read about the language groups browser, source bibliography, and chapter browser in the full documentation.
- Lexicon table: Search lexical data from Tibeto-Burman languages and varieties
- Etyma table: Locate reconstructions of Proto-Tibeto-Burman forms
- Language groups browser: Find information about languages and varieties in the database
- Source bibliography: Find bibliographical information about works included in the database
- Chapter browser: View the database by semantic category
In the upper left-hand corner of the interface is a drop-down menu which allows the user to switch between sections of the interface: 'Select...'. The two most important pages, which will be discussed here in the Quick-start Guide, are the lexicon table and the etyma table. (To switch between these pages choose 'Select... > Etyma' or 'Select... > Lexicon'.)
The lexicon table allows one to search the database for lexical entries from any of the languages and proto-languages contained in the database. The etyma table allows one to search the database for Proto-Tibeto-Burman etyma. (Some etyma from meso-languages, i.e. proto-languages reconstructed at the subgroup level, appear in the etyma table search results. These are stand-alone etyma which have not been found in languages outside a subgroup level and thus are not reconstructed for Proto-Tibeto-Burman, or they have not yet been linked to a Proto-Tibeto-Burman etymon because analysis is ongoing.)
It often is helpful to open up the lexicon table in one browser tab and the etyma table in another browser tab.
The lexicon table
The lexicon table is used to search all of the lexical entries in the database: reconstructed proto-forms from various publications; lexical data from Tibeto-Burman languages; Chinese comparanda; and select forms from languages which have contributed loanwords into Tibeto-Burman languages (Nepali, Old Mon, Proto-Hmong-Mien, Thai, etc.).
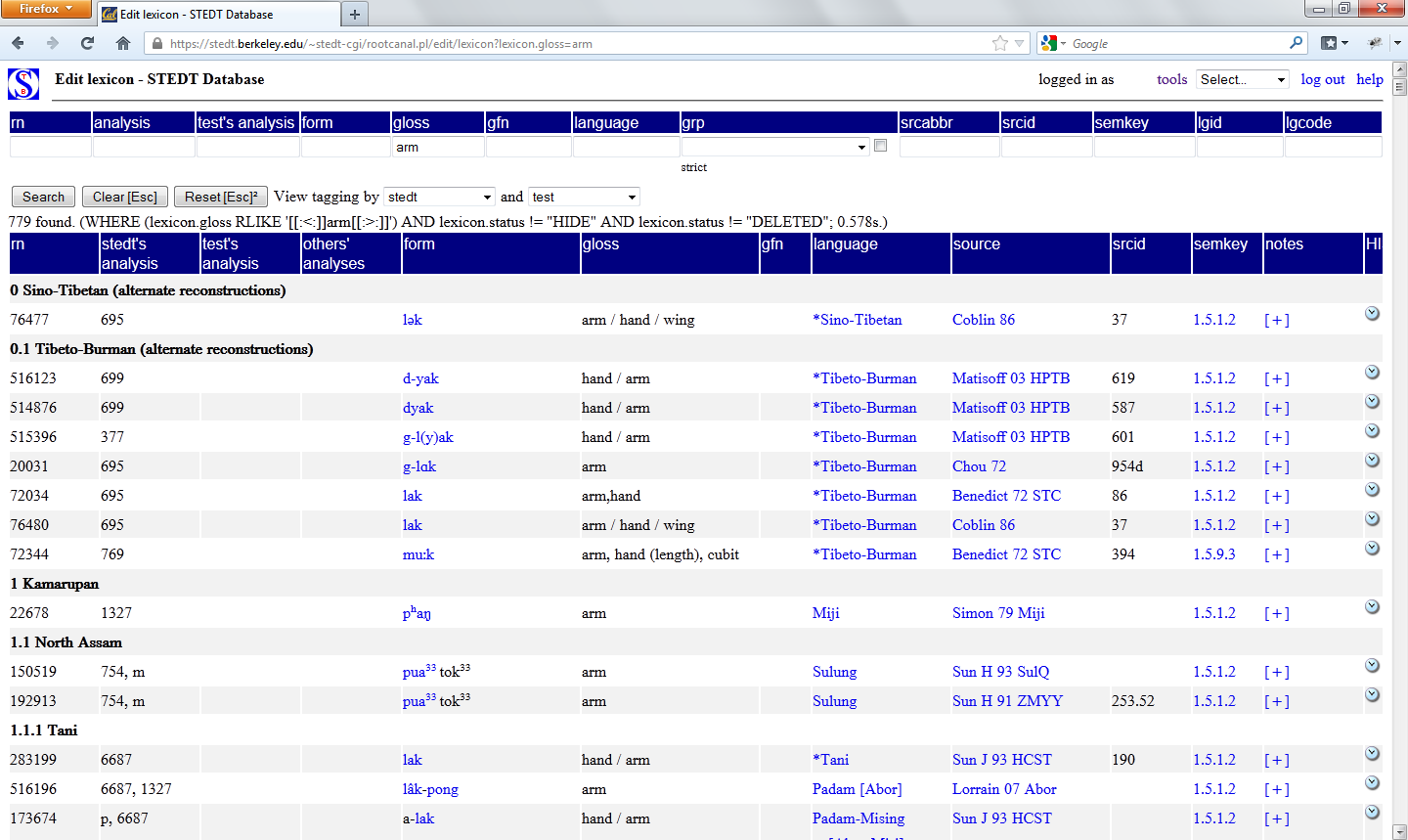
The lexicon table has two sections: the search fields (upper row) and the search results (lower rows).
The lexicon table has fifteen fields; the four primary search boxes are discussed here. Full documentation is available here.
The four primary search boxes are:
- form
- gloss
- language
- grp (language group)
You may search by entering a value in any of these four fields. The form search field searches all of the lexical entries in the database: reconstructed proto-forms from various publications; lexical data from Tibeto-Burman languages; Chinese comparanda; and select forms from languages which have contributed loanwords into Tibeto-Burman languages (Nepali, Old Mon, Proto-Hmong-Mien, Thai, etc.). The lexical data in the database have been compiled from many different sources, and are presented as transcribed by the researcher who collected the data. Thus, the same language variety may be transcribed in a number of different ways. Some transcriptions are in the International Phonetic Alphabet (IPA), while others are in romanization systems devised by the researchers who originally collected the data. Searches in Chinese characters or in Devanāgarī-based scripts are not supported.
The gloss field will search the database by the English meaning associated with each lexical entry. It will return partial matches associated with word boundaries, so a search for 'fish' will return results such as 'dried fish', 'fish sauce', and 'catch fish', but not 'fishing' or 'crayfish'. The search results may include a number of items which include the search term but are not directly related to your search. For example, a search for 'fish' includes gizigon 'sticks (iron, used for roasting fish etc. on fire)' from Bodo (Bhat 1968).
The language field will restrict the search by language name. For some languages, the database contains multiple varieties of the language. For example, for Tibetan, the database has 'Tibetan (Written)', 'Tibetan (Alike)', 'Tibetan (Amdo:Blabrang)', 'Tibetan (Amdo:Zeku)', 'Tibetan (Balti)', 'Tibetan (Batang)', 'Tibetan (Jirel)', 'Tibetan (Khams:Dege)', 'Tibetan (Lhasa)', 'Tibetan (Sherpa)', 'Tibetan (Spiti)', and 'Tibetan (Xiahe)'. Additionally, different researchers may have contributed data for some of these varieties, in which case there will be multiple entries for the same language variety for the same gloss. For additional information about the languages included in the database, see the language groups browser.
The grp field is a drop-down menu of the language groups contained in the database. When a language group is selected from the drop-down menu, the database will return only lexical entries for languages of that language group.
For any search, the maximum number of results returned is 10,000 entries.
These search boxes can be used in combination for advanced searches.
The search results are arranged by language family, with each language family or subfamily assigned an outline number: 1.1 North Assam, 1.1.1 Tani, and so on. The language families are arranged very loosely on an east to west basis, starting with the Tibeto-Burman languages of northeast India, through Burma, the Himalayas, and on to Southwestern China. Karenic and Sinitic appear towards the end.
As one can observe in the screenshot, the first listings in the search results are listings of alternate reconstructions for Sino-Tibetan and Tibeto-Burman. These are other possible reconstructions which have been proposed in the literature for your search word. Throughout the lexicon, one can identify a reconstructed form because reconstructed forms have an asterisk preceding the language name given in the 'language' field.
The etyma table
You will now want to select the appropriate Proto-Tibeto-Burman etymon from which your lexical entry(ies) descend. To view a complete listing of etyma, in a new browser tab, open the etyma table. The etyma table is available through a drop-down menu in the upper right-hand corner of the interface: 'Select... > Etyma'.
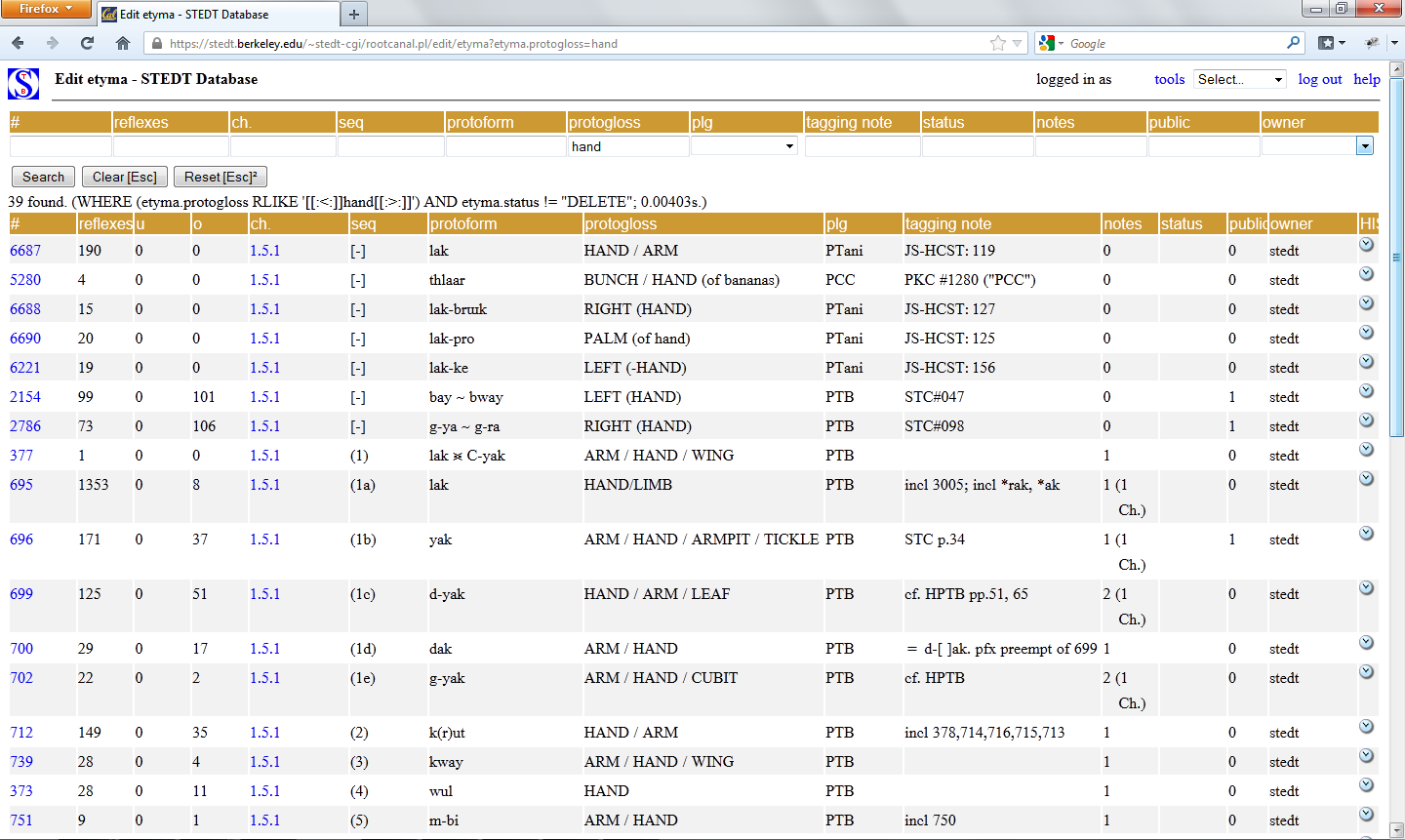
The etyma table is used to search the reconstructed proto-forms or etyma in the database. Most commonly, the etyma table is searched by proto-form or by proto-gloss. One can search the proto-form field by entering a known proto-form, or by entering a partial string, e.g. entering 'm' would yield all proto-forms which contain 'm'. One can search the proto-gloss field by entering a term in English, e.g. 'fish'; this will return all reconstructed proto-forms which contain the word 'fish', e.g. FISH, SKIN / LIP / SCALES (fish) / SHELL, FISH SCALES, and SHELL(-FISH). (Proto-glosses are given in capital letters in the etyma table.) The search results will appear in the search results (lower section) of the etyma table.
For a given gloss, there may be a number of different etyma within Tibeto-Burman. For example, there are a number of etyma which have been reconstructed for 'leaf': #824 *s-lap LEAF / LEAFLIKE PART, #293 *lay LEAF / PAPER, #708 *p(r)ak ⪤ r-pak ⪤ C-pak LEAF / PALM, #402 *s-nas LEAF, and others. Some forms may be borrowings, and there may be forms for which no etymon has yet been reconstructed.
The etyma table has twelve search fields (upper section) and and fifteen results fields (lower section). The four most important are described in this Quick-start Guide. Full documentation is available here.
- #
- protoform
- protogloss
- plg [proto-language]
# is the etymon's unique tag number. Each tag number has been assigned to its etymon arbitrarily. When one clicks on the tag number, a list of the reflexes in the daughter languages of the Tibeto-Burman family which support the reconstructed proto-form appears in a new tab, and any notes about the proto-form appear at the top of the page. Proto-form gives the reconstructed proto-form. The English gloss(es) for the etymon is given in the proto-gloss column. Finally, the proto-language column indicates to which proto-language the etymon belongs. The majority of the etyma given in the etyma table are reconstructed for Proto-Tibeto-Burman, but there are also etyma for PST / Proto-Sino-Tibetan, PTani / Proto-Tani, PKC / Proto-Kuki-Chin, PPC / Proto-Peripheral-Chin, PNC / Proto-Northern-Chin, PSPC / Proto-Southern-Plains-Chin, PCC / Proto-Central-Chin, PM / Proto-Maraic, PNN / Proto-Northern-Naga, PCN / Proto-Central-Naga, PTk / Proto-Tangkhulic, TGTM / Proto-Tamangic, PKir / Proto-Kiranti, PQ / Proto-Qiangic, PLB / Proto-Lolo-Burmese, PL / Proto-Loloish, PKar / Proto-Karenic, IA / Indo-Aryan, and undefined.
STEDT does not make any attempt to reconstruct Indo-Aryan forms; when an Indo-Aryan word has been pervasively borrowed into Tibeto-Burman languages, the Indo-Aryan word is assigned a tag number so that it can be tagged in the database. Thus, 'Indo-Aryan' is included in the Proto-language drop-down menu, and the user can search the database to see Indo-Aryan loans which appear with high frequency in Tibeto-Burman languages. (Please note, however, that less pervasive Indo-Aryan loans have not been assigned tag numbers. Additional Indo-Aryan loans can be viewed by searching the analysis field in the lexicon table for 'b' (e.g. 'borrowing'), 'bNep' ('borrowing from Nepalese'), 'bAssam' ('borrowing from Assamese'), 'b, Indic' ('borrowing from Indic'), 'b Hindi' ('borrowing from Hindi'), or searching the gloss field for 'Nepali', 'Sanskrit', 'Pali'. In some cases, footnotes give additional details as to the path of borrowing.) The 'undefined' etyma are mainly those which were given areal rather than genetic designations, i.e. KMR / Kamarupan, HIM / Himalayish, or other groupings which are no longer in use in the database; these etyma are in the process of being dealt with.
When the user conducts a search using the search fields in the etyma table, the search results appear below in a table. The search results table has the same fields, with two additions: u and o, which are the third and fourth search boxes from the left. U stands for user and o stands for other. U will list the number of reflexes which have been tagged by you for that etymon, while o lists the number of reflexes which have been tagged by all other users for that etymon. The value for 'o' appears as 'x:y', where 'x' is a number representing another user and 'y' is the number of reflexes tagged for the etymon by user x. (In both cases, the numbers given for 'u' and 'o' reflect tags which have not yet been approved by STEDT; when the tagging has been approved, 'u' and 'o' will appear as zero, and the tagging will be added to the number of approved reflexes in the reflexes field.)
An example
Let's take a concrete example. Say that you'd like to tag Cuona Menba (Bodic) tshik⁵³ 'joint' (Dai 1992). You have entered 'joint' into the gloss search field in the lexicon table browser tab, and have received (approximately) 426 lexical entries for this search term. Scroll down to 2.1.2 Bodic, and locate Cuona Menba tshik⁵³ 'joint'.
Next, you'll need to locate the appropriate Proto-Tibeto-Burman etymon with which to tag Cuona Menba tshik⁵³ 'joint'.
Switch to the etyma table browser tab, and search the protogloss field for 'joint'. Nine etyma appear for 'joint': PKC #4543 tsaaŋ ⪤ tsooŋ JOINT / JUNCTION, PTB #204 s-hwal JOINT / WRIST, PTB #418 tsik JOINT, PTB #426 swam JOINT, PTB #424 la JOINT, PTB #422 krok JOINT, PTB #425 sa JOINT, PTB #419 rik JOINT, and PTB #420 myan JOINT. You decide that the best analysis is that Cuona Menba tshik⁵³ 'joint' descends from PTB tsik JOINT. This etymon is #418.
Now, return to the lexicon table browser tab. Note that the third column from the left should read "[Your Username]'s analysis". (If a form has already been tagged, the tag number will appear in the second column, "STEDT's analysis", or in the fourth column, "others' analyses".) Scroll down to 2.1.2 Bodic, and locate Cuona Menba tshik⁵³ 'joint'. In the "[Your Username]'s analysis" column for Cuona Menba tshik⁵³ 'joint', type "418", and hit ENTER on your keyboard. (Please note that you must hit enter in order to save your tag. If you click out of the type box before hitting enter, your tag will not be saved.) Voilà, you have tagged your first reflex!
Other basic tags
p, m, s, b
As you will have noticed while examining the database, there are also a number of basic tags that are used to analyze lexical data in the STEDT database in addition to the numeric tags. These are p for prefix, m for morpheme, s for suffix, and b for borrowing. p and s should only be used when the tagger knows that the morpheme is in fact a prefix or suffix, respectively. When there is a morpheme, but the tagger is not sure whether it is an affix or a morpheme, s/he should tag it as m for morpheme. When there is more than one morpheme per word, each morpheme should receive a tag, even if it is just 'm'. (Note, however, that if none of the morphemes are known, one should not tag such forms as 'm, m' or 'm, m, m', etc.)
Thus, if one knows that the 'a' in Written Burmese a khak 'branch' is a prefix, one can tag this form as p, m. Commas are always used between tags. If one finds that the 'khak' in Written Burmese a khak is a reflex of #1278 PTB *s-ka(ː)k FORK / BRANCH / CROTCH, then one can tag this form as 'p, 1278'. In a few cases, a suffix may be assigned a tag number or tagged as 's'. For example, for Written Tibetan bya mo 'hen', the suffix marks that the animal is female and can be analyzed as descending from #1620 PTB *mow FEMALE / WOMAN / BRIDE. In such cases, tagging the suffix as 's' is also fine.
The b tag is used to indicate a borrowing. The tagger can add a footnote to the lexical entry by clicking on the '+' sign in the far right-hand notes column. Such footnotes can indicate the language from which the word was borrowed, the source word (Chinese characters and Devanāgarī-based scripts are supported in this field, but please add a romanization for users not familiar with these scripts), or other relevant etymological notes.
The STEDT delimiter ◦ and the STEDT overriding delimiter |
Lexical entries often do not have morphological boundaries marked. Thus, before one can tag a morpheme, one frequently needs to indicate a morphological boundary; an added morphological boundary is represented with the ◦ symbol and is called a STEDT delimiter. One can add a STEDT delimiter by clicking one's cursor where one would like to insert a boundary in the form, clicking the keyboard's space bar, and hitting ENTER. For example, if one saw the Ergong (Danba) (Sun 1991) form ɬɯva 'moon', and one wanted to tag the first syllable as a morpheme descending from #1016 PTB *s-(g)la MOON, one would first need to enter a delimiter so that the form reads ɬɯ◦va. One can then tag this form as '1016, m'. After one enters a STEDT delimiter to a form, it will be visible as a small circle ◦ only when one clicks on the form field. This allows us to know that the analysis of this morphological boundary did not appear in the original source, but rather was added later, and is thus part of the analysis.
Occasionally, one needs to override a morphological boundary that already exists, or a hyphen that the database is treating as a morphological boundary. In a form such as #2666 PTB *g-sum THREE (Benedict 1972, Chou 1972, LaPolla 1987, Weidert 1987), the tag should refer to the entire form, *g-sum. However, because some sources use hyphens to represent morphological breaks, the tag will not attach to the entire form unless one overrides the hyphen using the STEDT overriding delimiter |. The overriding delimiter | usually is located above the ENTER button on keyboards, and requires use of the shift key. It is inserted directly following the hyphen or morphological break that one wants to override, like so: g-|sum. Like the STEDT delimiter, the STEDT overriding delimiter is visible only when one clicks on the form field.
Deprecated tag: !
There is a deprecated tag that has not yet been removed from the STEDT database. ! was used early in the project's history following a tag number to indicate that the tagger was unsure about the tag or that the form showed an anomaly in its historical phonological development. This tag should not be used.