Methodology
Preparation of sources for etymological analysis
Data collection involves literally hundreds of dictionaries, wordlists, and solicited questionnaires describing in varying levels of detail the lexica of the more than 200 TB languages. These data sources vary widely in their age, quality, and integrity, and require different processing strategies. A large part of the STEDT project involves the integration of these sources into the STEDT database.
Carrying out etymological analysis
Roots, or etyma, are reconstructed according to the time-tested principles of the comparative method: searching for cognate sets by identifying lexical items with similar phonological and semantic shape, working out regular correspondences and sound laws, and determining the phonological system of the reconstructed proto-language. These tasks are necessarily constrained in the case of the STEDT project by the unique characteristics of the Sino-Tibetan language family.
PST and PTB were fundamentally monosyllabic, and most of their modern descendants remain so today. However, in most ST languages compounding has reached an advanced stage, resulting in polysyllabic forms in which each syllable is a morpheme with a distinct origin. Thus a single word may be associated with two or more proto-roots. The goal of the STEDT project is to associate each morpheme of every lexical item with a single etymon. This means that in many cases a word will appear in more than one location in the STEDT volumes, listed under each of the roots with which it has been associated.
Hundreds of etymologies have already been proposed, identifying genetically related words in various ST languages. These etymologies are not equally plausible or mutually consistent. A major task of this project, especially in its early stages, has been to sift through the entire corpus of etymologies that have been suggested by serious scholars, to compare, evaluate and discuss them, and decide which ones to retain and which to modify or reject. Scrupulous care has been exercised in attributing any given etymology to the scholar who first proposed it (either in print or via personal communication). Equally important, the large amount of data at our disposal has permitted the reconstruction of hundreds of new etyma in the semantic area of bodyparts alone.
Special attention is paid to the patterns of phonological variation displayed by each proto-root. As in Indo-European, ST etyma are not invariant in shape, but form clusters of morphophonemically related sub-roots, which have traditionally been referred to as word families. The "allofams" of a word family may differ from each other by their prefixes, by the voicing or voicelessness of their initial consonant, by their nuclear vowel, by their final consonant, and/or by their tone. These patterns of variation are not random, but fall into certain well-defined classes of phenomena. Great care needs to be exercised in attributing particular forms in modern languages to the particular proto-allofam from which they descend.
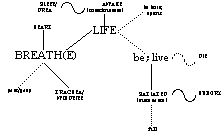 Semantic variation and shifting are just as essential to trace through time as phonological evolution. Certain semantic associations can be backed up by phonological evidence (cf. BREATH(E)/LIFE/LUNG), but others cannot. Diagrammatic representations of the patterns of historical semantic association in TB/ST are an integral part of STEDT, via "metastatic semantic flowcharts", such as the one shown here.
Semantic variation and shifting are just as essential to trace through time as phonological evolution. Certain semantic associations can be backed up by phonological evidence (cf. BREATH(E)/LIFE/LUNG), but others cannot. Diagrammatic representations of the patterns of historical semantic association in TB/ST are an integral part of STEDT, via "metastatic semantic flowcharts", such as the one shown here.
The actual work of etymologization is done using the computer tools described on the Database and software page. Etymologies are continually revised in the light of new data as it becomes available. Extensive notes discussing general considerations and the finer points of individual etymologies are entered into the database and will constitute a vital part of the finished STEDT volumes.